I run my OKD cluster on a set of VMs in VMware ESXi. My backups consist of shutting down all VMs and then copying them somewhere else – so full shutdown and backup.
The cluster setup was done using the steps outlined in OKD 4.5 small cluster on ESX.
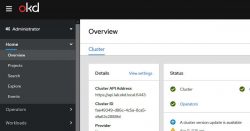
This has worked well and I have been able to restart the OKD cluster after a full restore with no issue. But now the cluster doesn’t start, OKD web console doesn’t work and when I monitor the VMs and ESX host the CPU, RAM, Disk and Network resources are all really low.
I struggled a long time to figure out how to start up what is essentiallya really old VM backup set. I finally got it figured, I think, but this is on the basis of the steps, order and timing I have outlined below.
So I am now starting up a full backup set that was backed up on 13/1/2021 and today is the 14/3/2021.
I have two ESXi servers, “HP3” has the services and control-plane nodes and “Lenovo5” has the computer/worker node.
Failed restore
To demonstrate the problem I started the services node and the control pane node. These two nodes are both on the “HP3” ESX server. The below is the memory and CPU usage for 24 minutes after I started these nodes. As you can see there was very little activity. I started the nodes at 19:14:


When you try to login you just get:

Prechecks
Before starting check that the date and time are correct on all ESX servers so the initial time for the VMs will all be more or less in sync with each other prior to NTP kicking in.
Services node
To begin with only start the services node as this doesn’t actually start OKD and is important as it needs to provide NTP, DNS and Proxy services.
There are some below things you should ensure are done prior to starting the other nodes.
Add a firewall rule for NTP and restart:
firewall-cmd --permanent --zone=public --add-port=123/udp
systemctl restart firewalldThen I edit the chrony config. So backup and then edit “/etc/chrony.conf”. For me, in New Zealand, this is the chrony.conf file I used:
#
# Example chrony file from zoyinc.com
#
# Using New Zealand NPT servers - Please set to your local NTP public servers
#server 43.252.70.34
server 0.pool.ntp.org
server 1.pool.ntp.org
server 2.pool.ntp.org
server 3.pool.ntp.org
server 216.239.35.0
server 216.239.35.4
# Record the rate at which the system clock gains/losses time.
driftfile /var/lib/chrony/drift
# Allow the system clock to be stepped in the first three updates
# if its offset is larger than 1 second.
makestep 1.0 3
# Enable kernel synchronization of the real-time clock (RTC).
rtcsync
# Allow NTP client access from local network.
allow 192.168.0.0/16
# Serve time even if not synchronized to a time source.
local stratum 10
# Specify directory for log files.
logdir /var/log/chrony
# Select which information is logged.
log measurements statistics trackingNow restart:
systemctl restart chronyd.serviceCheck the sources for chrony by running “chronyc sources”: This should return something like:
[root@okd4-services ~]# chronyc sources
210 Number of sources = 6
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^? time1.google.com 1 6 1 28 -984us[ -984us] +/- 80ms
^? time2.google.com 1 6 1 28 -18us[ -18us] +/- 60ms
^? ns1.att.wlg.telesmart.co> 2 6 1 29 -1792us[-1792us] +/- 14ms
^? ip-103-106-65-219.addr.l> 2 6 1 30 -576us[ -576us] +/- 38ms
^? 101-100-146-146.myrepubl> 2 6 1 30 +962us[ +962us] +/- 52ms
^? ns2.tdc.akl.telesmart.co> 2 6 1 30 -813us[ -813us] +/- 6027usIt appears that the worker/master nodes will use UTC so for consistency enable UTC on the services VM by running:
timedatectl set-timezone UTCInitial startup
Now that the services node is up and configured start up the control plane node – do NOT start the compute/worker node yet.
On the services node run:
export KUBECONFIG=/opt/okd4/install_dir/auth/kubeconfig
oc get csrBecause you have just started the Control Pane this will return:
[root@okd4-services ~]# oc get csr
Unable to connect to the server: x509: certificate has expired or is not yet valid
[root@okd4-services ~]#Keep running “oc get csr” until you get a certificate. You may see the following while you wait for it to start
[root@okd4-services ~]# oc get csr
No resources foundThis could take a few minutes so be patient:
[root@okd4-services ~]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-jnpdf 28s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper PendingApprove this certificate using “oc adm certificate approve <csr name>”:
[root@okd4-services ~]# oc adm certificate approve csr-d5gt4
certificatesigningrequest.certificates.k8s.io/csr-d5gt4 approved
[root@okd4-services ~]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-jnpdf 42s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,IssuedKeep looking for approvals, we are expecting a “system:node” csr for the control plane. It will look like:
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-55m7p 19s kubernetes.io/kubelet-serving system:node:okd4-control-plane-1.lab.okd.local Pending
csr-d5gt4 63s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,IssuedYou need to also approve this as before:
[root@okd4-services ~]# oc adm certificate approve csr-55m7p
certificatesigningrequest.certificates.k8s.io/csr-55m7p approved
[root@okd4-services ~]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-55m7p 41s kubernetes.io/kubelet-serving system:node:okd4-control-plane-1.lab.okd.local Approved,Issued
csr-d5gt4 85s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,IssuedWait for web console to come up
At this point simply wait for the web console to come up, this could take 10 minutes. Once the web console comes up you will also see a lot more CPU activity and memory usage compared to the earlier screenshots when OKD didn’t start.


Start the compute/worker node
Now that the web console is up you will be able to see some things but some things are still not showing:

So now start the compute/worker node.
As before keep monitoring for csrs by running “oc get csr” on the services node.
[root@okd4-services ~]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-2d68r 26s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending
csr-jnpdf 15m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-rxwww 14m kubernetes.io/kubelet-serving system:node:okd4-control-plane-1.lab.okd.local Approved,IssuedApprove the certificates as they come through. Once this is stabilized you should see:
[root@okd4-services ~]# oc get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
csr-2d68r 2m4s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-jnpdf 17m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Approved,Issued
csr-rxwww 15m kubernetes.io/kubelet-serving system:node:okd4-control-plane-1.lab.okd.local Approved,Issued
csr-wlbkc 61s kubernetes.io/kubelet-serving system:node:okd4-compute-1.lab.okd.local Approved,IssuedIt is worth noting that the above 4 certificate signing requests include one each for the control plane and compute node plus an equal number of bootstrap requests.
In say 5 minutes you should see the web console looking much healthier:

The CPU and memory on the HP3 ESX host also looks a lot healthier. Note I started the control plane node at 19:33 and the compute node at 19:56: